일반적인 데이터베이스에서 검색을 할 때는 검색하는 요소가 포함되어 있는지를 찾게 됩니다.
하지만 우리는 검색엔진을 이용할 때 단순히 단어만 입력하지 않습니다.
문장을 입력해도, 동일한 문장이 포함되어 있진 않지만 유사한 내용을 보여 줍니다.
간단히 벡터데이터베이스와 임베딩을 이용하여 사례를 통해 그 원리를 살펴보겠습니다.
https://foreducator.com/chat_embeddings/chat/
위 사이트는 현재 생활기록부 관련 자료를 벡터데이터베이스와 sqlite3에 인덱스를 중복하여 함께 저장해 놓고
사용자의 입력과 유사한 내용을 검색해서 보여주는 구조로 이루어졌습니다.
예를 들어, '생활기록부 진로활동에 여러개를 중복해서 적어도 돼?' 라는 질문을 던져보겠습니다.
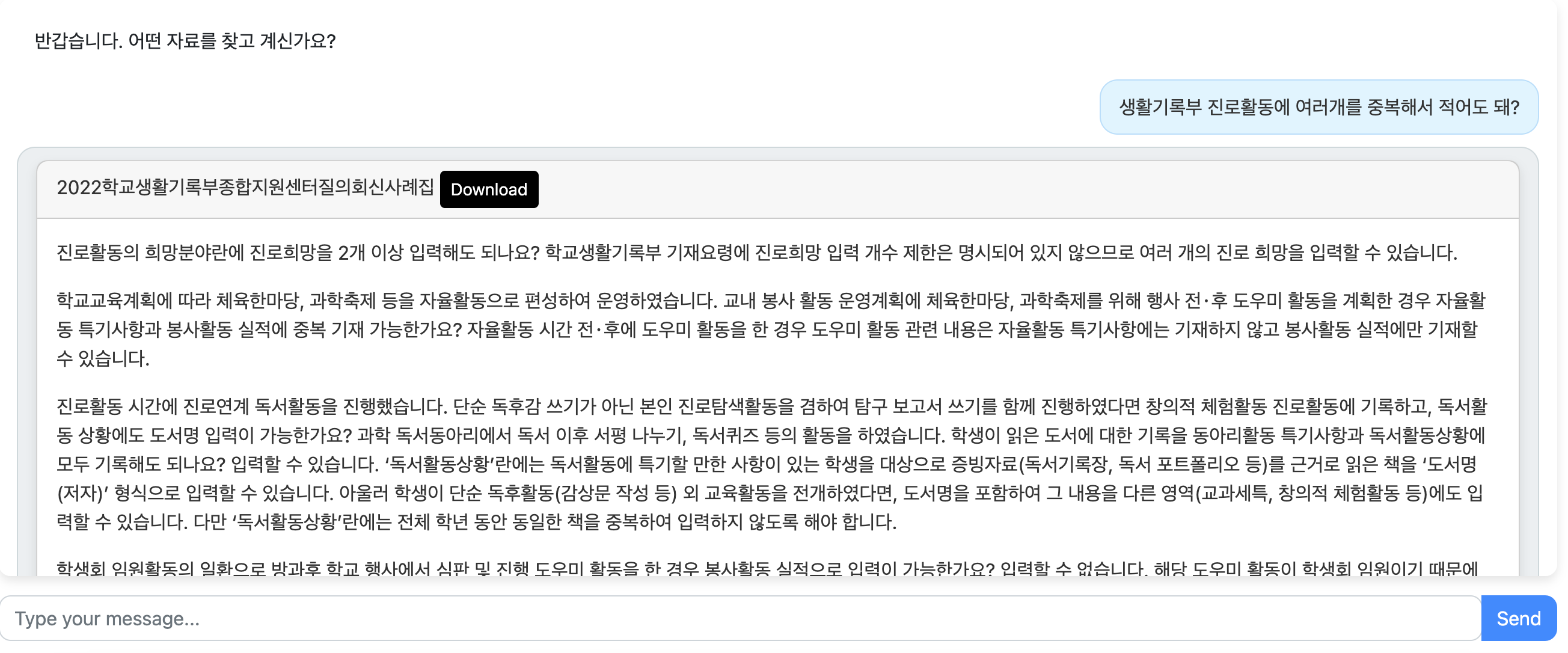
입력한 내용과 동일한 문장이 포함되진 않지만 유사한 문장이 있는 내용을 출력해 주는 것을 볼 수 있습니다.
어떤 구조로 진행되는 건지 알아보겠습니다.
먼저 사용자가 입력한 메세지를 벡터로 전환합니다.
이런 과정을 임베딩이라고 하는데, 직접 라이브러리를 이용할 수도 있지만, 임베딩 모델의 성능에 따라서 그 결과의 차이가 존재 할 수 있어 openAI에서 제공하는(text-embedding-ada-002)를 이용합니다.
사용자의 메세지를 ada-002를 통해 변환하면 숫자가 ,로 구분되어 1536개의 숫자리스트로 문장을 바꿔줍니다.
즉, 1536차원의 벡터로 변환해준 것입니다. 각 임베딩 모델별로 고유한 규칙으로 문장을 변환하므로 동일한 모델 ada-002를 통해 벡터데이터베이스에도 미리 자료들을 저장해 둔다면
사용자가 입력한 내용과 유사한 내용을 찾을 수 있게 됩니다.
현재 벡터데이터베이스에는 이미 벡터화되어 있는 자료들이 있습니다. 이 벡터들은 모두 ada-002로 임베딩되어 차원도 모두 동일합니다.
이 때 비슷함을 측정해야 하는데, 비슷한 곳에 있으면 비슷하다고 여깁니다.
그렇지만 유클리드 거리를 사용하기보다 코사인 유사도를 사용합니다.
코사인 유사도란 두 벡터사이의 이루는 각이 작을 수록 두 벡터가 유사하다고 판단하기 위해 벡터 사이의 각을 계산하는데,
이 때 벡터의 내적이 코사인 값과 유사하여 쉽게 계산할 수 있습니다.
결과적으로 이 유사도 값이 1에 가까울 수록 유사한 벡터라는 것이고, 유사한 의미의 문장으로 판단하는 것입니다.
임베딩된 벡터는 원래의 데이터를 아주 작게 만들어 낸 것입니다. 그렇기에 데이터를 원형으로 복구하는 것은 불가능합니다.
따라서 임베딩하면서 본래의 데이터를 어딘가에 보관해야만 다시 출력이 가능하겠죠?
이를 위해 벡터에 메타데이터를 추가하는 방법도 있고
sql DB를 추가로 연결해서 사용할 수도 있습니다.
위 사이트는 장고에서 사용하는 sqlite3와 벡터데이터베이스의 각 요소의 id값을 일치시켜
사용자가 입력하면 이를 임베딩하고, 임베딩한 벡터와 유사도 높은 벡터들을 찾고, 해당 벡터의 실제 내용을 찾기위해 sqlite3 데이터베이스를 탐색하여 그 결과를 보여주는 구조로 이루어진 것입니다.
