22년 11월, ChatGPT3.5를 출시하며 인기를 끌기 시작한지 이제 딱 1년이 지났다. 하지만 그 변화와 발전의 속도는 매우 놀랍다. 23년 3월 GPT4를 출시하며 그 성능을 대폭 업그레이드 시킴과 동시에 여러 플러그인을 결합하여 몇 몇 한계를 극복하기도 했다.
대표적으로 수학 계산과 관련한 답변을 준비할 때는, WolframAlpha와 연동하여 보다 정확한 답을 구할 수 있게 되었다. 더 나아가 7월에는 Data Analysis라는 기능을 추가하여 직접 파이썬 코드를 작성하여 식을 계산하거나, 통계적 자료를 분석하는 등의 작업을 스스로 진행한 후, 이를 토대로 정확한 답변을 낼 수 있게 된다. 이를 사용하기 위해서는 내가 하고자 하는 작업에 맞게 플러그인을 선택하거나 DataAnalysis탭을 선택하고 작성해야 했다.
하지만 이 글을 작성하고 있는 23년 11월 업데이트를 통해 메뉴의 선택 없이 편하게 사용자가 입력하면 입력한 메시지를 토대로 자동으로 플러그인을 활용할지, 코드를 작성하여 계산할지, 웹검색을 통해 추가 자료를 얻을지, 심지어 그림을 그려줄지 등을 스스로 선택한 후 답변을 할 수 있게 되었다.
이처럼 ChatGPT가 각광받기 시작한 지, 이제 1년이 지났을 뿐인데 그 발전 속도는 놀랍다. 다른 업체들까지 인공지능개발에 뛰어 들고 있으니 그 발전 속도는 더욱 빠를 것이다. 이미 다량의 데이터를 분석하는 일은 훌륭하게 수행한다. 약 30,000명의 육군 신체측정정보를 담은 엑셀파일을 ChatGPT에게 업로드 파일 업로드하고 통계분석을 부탁해 보았다. 평균, 표준편차등의 간단한 정보 뿐만 아니라 상관관계를 분석하거나 원하는 그래프를 요청하면 그래프를 얻을 수도 있다. 복잡한 과정이 아니다. 단순히 ‘신장 정보를 시각적으로 표현해줘.’와 같은 문장을 전달하기만 하면 된다. 결과가 만족스럽지 않다면 ‘다른 방법으로 표현해줘.’ 혹은 직접 원하는 형태를 지정하여 ‘상자 그림으로 표현해줘.’ 와 같이 다시 물어보면 원하는 답을 결국 얻을 수 있게 된다.
이런 상황에서 잠시 중학교 1학년 통계단원의 성취기준 하나를 살펴보자.
[9수05-01]자료를 줄기와 잎 그림, 도수분포표, 히스토그램, 도수분포다각형으로 나타내고 해석할 수 있다.
어느 단원이나 유사한 형태의 진술 방식이다. 성취기준은 굉장히 결과지향적으로 작성되어 있으며, 교사들은 이를 학생 평가의 기준으로 삼는다. 그렇기에 과정이 중심이 된 평가가 이루어지기 어려운 것이다.실제 과정을 중요하게 여긴다는 많은 선생님들도 과정을 평가하는 기준은 결과적 모습이다. 학생들이 결과적으로 성공해야 과정이 잘 진행되었다고 판단하고 있는 자신의 모습을 부정하기 어려울 것이다.
따라서 성취기준은 과정지향적으로 변화할 필요가 있다. 물론 ‘성취기준’이라는 용어자체도 함께 수정되길 바란다. 잠시 생각해보자. 학생들이 ChatGPT를 이용하여 주어진 자료를 완벽하게 정리하고, 시각화하고, 분석 및 해석을 진행했다. 이 학생은 성취기준을 달성했다고 볼 수 있을까? 만약 여기에 동의한다면 수업의 본질은 무엇인지, 학생들이 배운다는 것은 어떤 의미인지 한 번 되돌아 보길 바란다.
과정중심적이며 학생의 배움을 중심으로 작성된 성취기준은 아직 없다. 따라서 기존의 성취기준을 재해석하며 자신만의 성취기준을 만드는 것이 필요하다. 각자가 목표로 하는 수업, 이상적인 배움의 모습이 다르기에 서로 다른 결과를 도출할 수 있다. 내가 생각하는 수업의 목표에 비추어 볼 때, 위에서 예로든 ChatGPT를 활용한 결과를 제출한 학생은 배우지 못했다. 기존의 성취기준을 살펴보면 자료를 통계적도구를 사용하여 표현하고 해석할 수 있는 학생으로 성장시키고 싶은 것처럼 보인다. 이는 단순히 결과물을 제출할 수 있는지 여부로 판가름나지 않는다. 자료를 통계적 도구로 표현한다는 것은 자료를 살펴보고, 그 자료에 어떤 통계적 도구가 적합할 것 같은지 고민하고, 선택하고, 여러 가지로 표현해보며, 실제로 무엇이 더 어울리는지 비교하는 등 다양한 학생의 경험을 포괄하고 있는 것이다. 그리고 이러한 경험을 학생에게 제공하는 것이 수업의 목적이며, 이러한 경험을 통해 학생이 성장한다면 그것이 배움이라 생각한다.
이러한 입장에서 어떤 경험이 학생에게 필요한지 고민해보자. 잠시 성취기준 ‘자료를 줄기와 잎 그림, 도수분포표, 히스토그램, 도수분포다각형으로 나타내고 해석할 수 있다.’를 다시 살펴보자. 먼저 자료를 여러 도구로 나타내야 한다. 그러려면 학생들에게는 그렇게 해야할 필요가 요구된다. 즉, 자료를 보고 뭔가 다른 방법으로 정리해야만 하겠다고 느끼게 만들어야 한다. 그럼 학생들 입장에서 언제 정리할 필요하다고 느껴질까? 아마 소재는 흥미로운데 자료만 봐서는 무엇을 나타내는지 쉽게 파악하기 어려워야 할 것이다. 그러려면 실제의 많은 데이터가 필요할 것이고, 자료가 많을수록 통계는 더욱 강력함을 자연스럽게 느낄 수 있을 것이다. 또한 스스로 자료를 정리할 필요를 느꼈다는 것은, 이미 해석을 염두에 둔 결정이다. 따라서 기존의 성취기준에서 핵심은 학생들에게 자료정리의 필요성을 부각시키는 일이 되는 것이다.
새롭게 성취기준을 만들어 본다면 다음과 같은 형태로 학생들의 경험을 서술하길 기대한다.
1. 추가적인 분석없이 데이터의 특성을 파악하기 힘든 대량의 데이터를 접하며, 자료 정리의 필요성을 인식한다.
2. 자신의 의도에 맞게 자료를 정리하고 표현한다. 이는 기존의 ‘해석할 수 있다.’가 자연스럽게 선행된 후 자료를 정리하고 표현하게 될 것이고, 이는 통계적 도구를 해석하는 역량을 기르는데 보다 적합한 방법이다.
이렇게 성취기준에 대해 재해석하고 필요한 학생들의 경험을 선정했다면, 문제는 대량의 데이터를 확보하는 일이다. 하지만 이는 사실 쉽지 않다. 통계청 등 통계 정보를 제공하는 다양한 사이트가 있지만, 대부분 이미 정제된 데이터를 제공하고, 원본의 데이터를 제공하는 일은 매우 드물다. 하지만 학생들이 학습해야 하는 것은 통계청에서 데이터를 정제한 그 과정, 왜 그렇게 자료를 정리했는지에 대한 경험이 학생들에게 필요한 것이기에, 통계청의 자료는 학습자료를 구성할 때 크게 도움이 되지 못한다.
하지만 이제 ChatGPT를 이용하면 통계청에서 제시하는 통계적 수치에 맞게 가상의 데이터를 생성할 수 있다. 실제와 통계적 정보는 동일하지만 가상의 원본 데이터를 만들 수 있게 된 것이다. 예를 들어 통계청에서 다음과 같이 10분위별 가구 소득 정보를 얻을 수 있다.

이 데이터를 통계청에서 엑셀로 다운로드 받은 후 ChatGPT에 업로드를 시킨다. 그리고 ‘위와 같은 특징을 동일하게 가지는 1000개의 가상의 원본데이터를 엑셀파일로 만들어줘.’ 와 같은 메시지를 전달하면 엑셀파일을 다운로드 할 수 있게 해준다. 메시지나 자료에 따라 오류가 있을 수 있으니 점검해보고 싶어 ‘생성한 자료를 시각적으로 표현해줘.’라고 부탁해보니 다음과 같은 형태의 그래프를 제시하였다. 그래프를 확인하면 의도에 맞게 데이터가 생성되었는지 쉽게 검증할 수 있다.
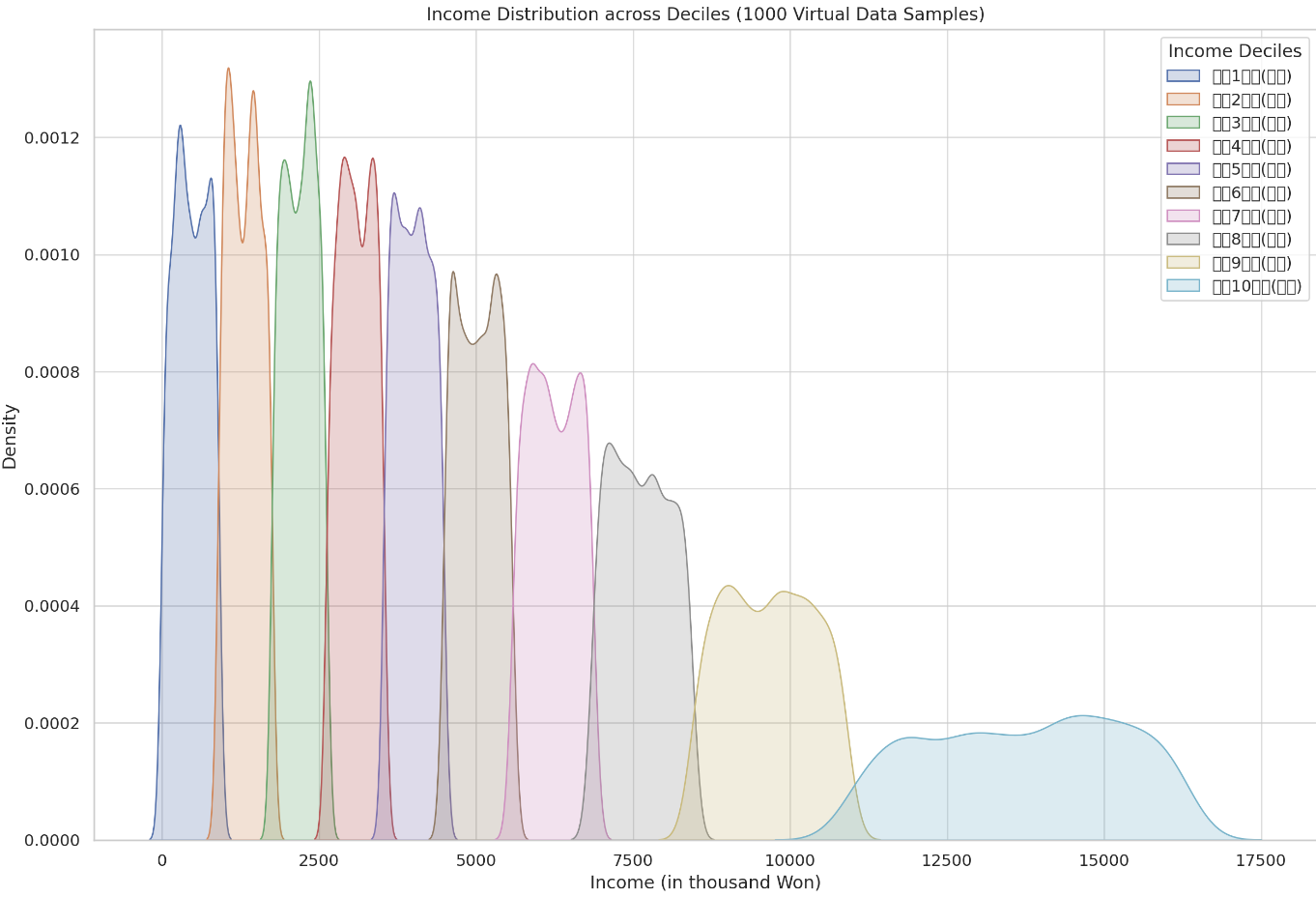
앞으로 새로운 공학적 도구는 계속 개발될 것이다. 그리고 더욱 뛰어난 성능과 편리한 사용성을 제공할 것이다. 하지만 수업에서 이는 항상 좋은 것은 아니다. 성능이 좋아지고 더욱 편리해질수록 오히려 학생이 해야할 많은 경험들을 빼앗아갈 수 있기 때문이다. 수업에서 공학적 도구를 사용할 때는 학생에게 어떤 경험이 필요한지를 항상 먼저 고민해야 한다. 그러고 난 후, 그 경험을 제공하기에 새로운 도구가 어떻게 사용될 수 있는지 생각하고, 적합하다고 생각될 때에만 사용해야 한다.
사실 요즘은 학생들에게 공학적 도구보다 적절한 어려움과 그 어려움을 극복하기 위한 고민의 시간들이 더욱 절실해 보인다.
